Server IP Ranges
Kotlin library for cloud provider IP range verification
TL;DR
- A Kotlin library that identifies cloud provider IP ranges (AWS, GCP, Azure, etc.) for access control.
- Based on experience requiring cloud-range-based blocking to prevent public API abuse, it was designed with the goals of reflecting up-to-date IP ranges and optimizing verification performance.
- It consists of an IP range collection and storage pipeline and an in-memory verification engine, and can be easily integrated as a library into existing JVM services such as Spring Boot.
- It was open-sourced based on in-house service adoption experience.
Planning
Background
This project started from an IP blocking system that was built to prevent abuse in a public API service operated by my team.
The service was integrated as a built-in feature into the search results of major Korean portals (Naver and Daum), handling over 500,000 requests per day.
Because of the nature of a public service accessible to anyone, large-scale abusive traffic using various methods such as macros and scraping was unavoidable. This went beyond distorting service metrics and also affected core services connected to it, becoming a major threat to operational stability.
Initially, I responded by introducing per-IP rate limiting, but it could not handle IP rotation using dynamic IPs in cloud environments.
In the end, I needed to develop a means to identify cloud ranges themselves in order to block cloud-based bypass attacks at the source.
Goals
1. Provide Up-to-Date IP Ranges
Cloud providers frequently change IP ranges depending on network and service conditions. Even if all IP ranges are blocked today, abusive attacks can come from newly added ranges tomorrow.
To block irregular abuse traffic at the source, I needed to reflect cloud providers’ IP range updates in real time.
2. Optimize CPU / Memory Performance
Cloud providers operate infrastructure at global scale.
If IP ranges across all those data centers are fetched and loaded into memory every time, that itself becomes a major server load.
Also, if every incoming IP to verify is matched against all candidates one by one, high latency is expected in high-traffic environments.
To solve these problems, it was necessary to reduce IP data according to use cases and optimize the data structure to improve verification speed.
3. Easy Integration with Existing Services
The functionality targeted by this project can be summarized as “a boolean-returning function that verifies whether a specific IP belongs to a cloud range,” so building a separate server would be over-engineering.
At the same time, I needed to provide a minimal, simple interface and enable fast integration with the existing Spring Boot-based tech stack, so I adopted a library form that satisfies both.
Development
Tech Stack
This project was written in Kotlin for the following advantages:
- 100% compatibility with existing
JVM-Spring-based services - Support for Kotlin-first
Kotlin+Springenvironments - Null type safety when handling external APIs / file I/O
- Serialization handling using
kotlinx.serialization - Logic readability through concise syntax
- Easy coroutine-based asynchronous handling during extension
Architecture
The architecture of this project is broadly divided into two parts: the part that collects and stores cloud providers’ IP ranges and the part that loads stored IP ranges and verifies them.
Cloud IP Range Collection
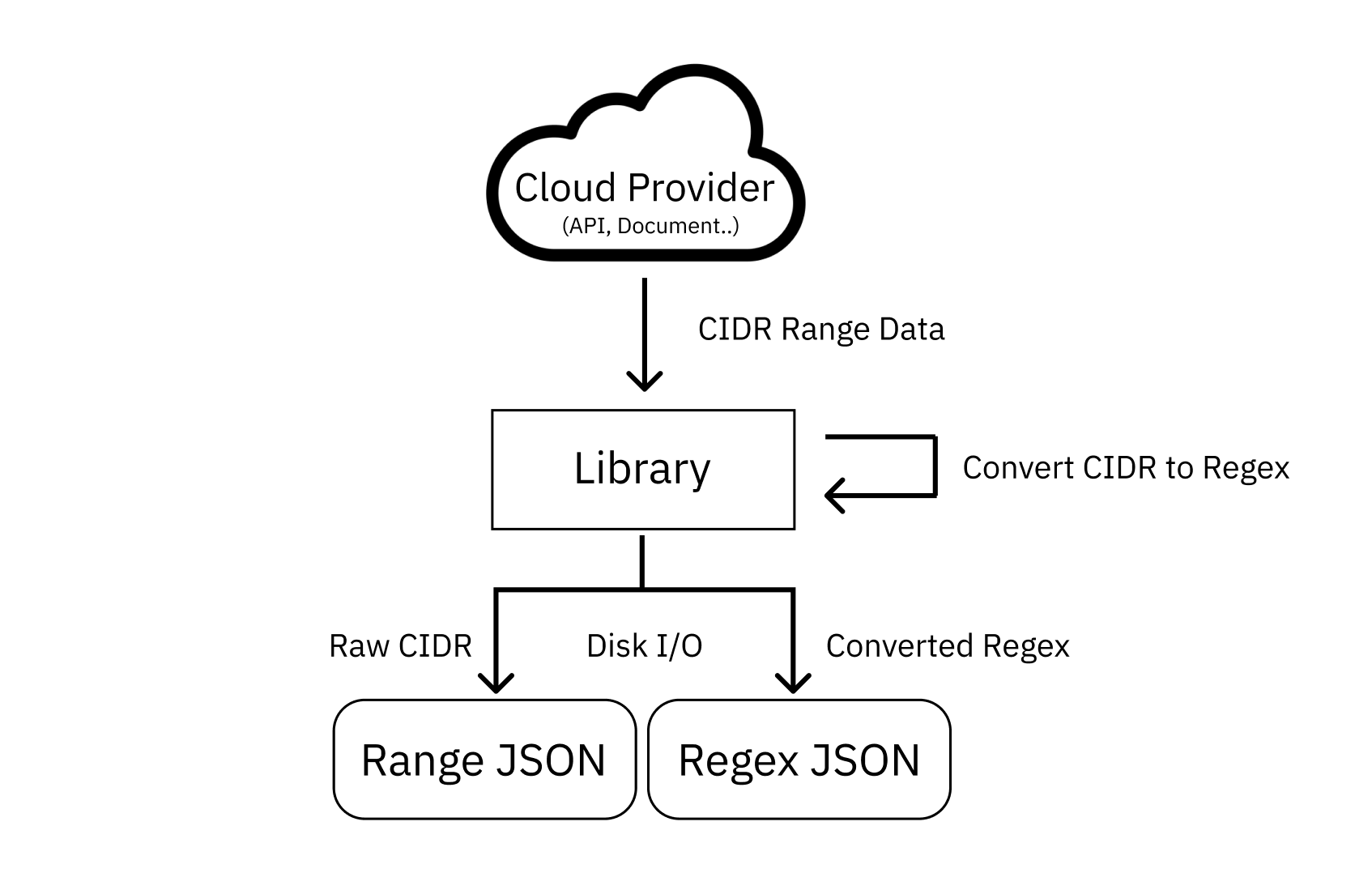
It parses CIDR-formatted IP range data published by cloud providers and refines it according to predefined classification rules (Provider, Region).
Then, to make it usable for verification, it converts CIDR into regex and stores it as JSON files. During verification, the library reads regex patterns stored in these files to validate IPs.
For backup and history tracking, the refined source CIDR data is also stored in JSON format.
IP Range Verification
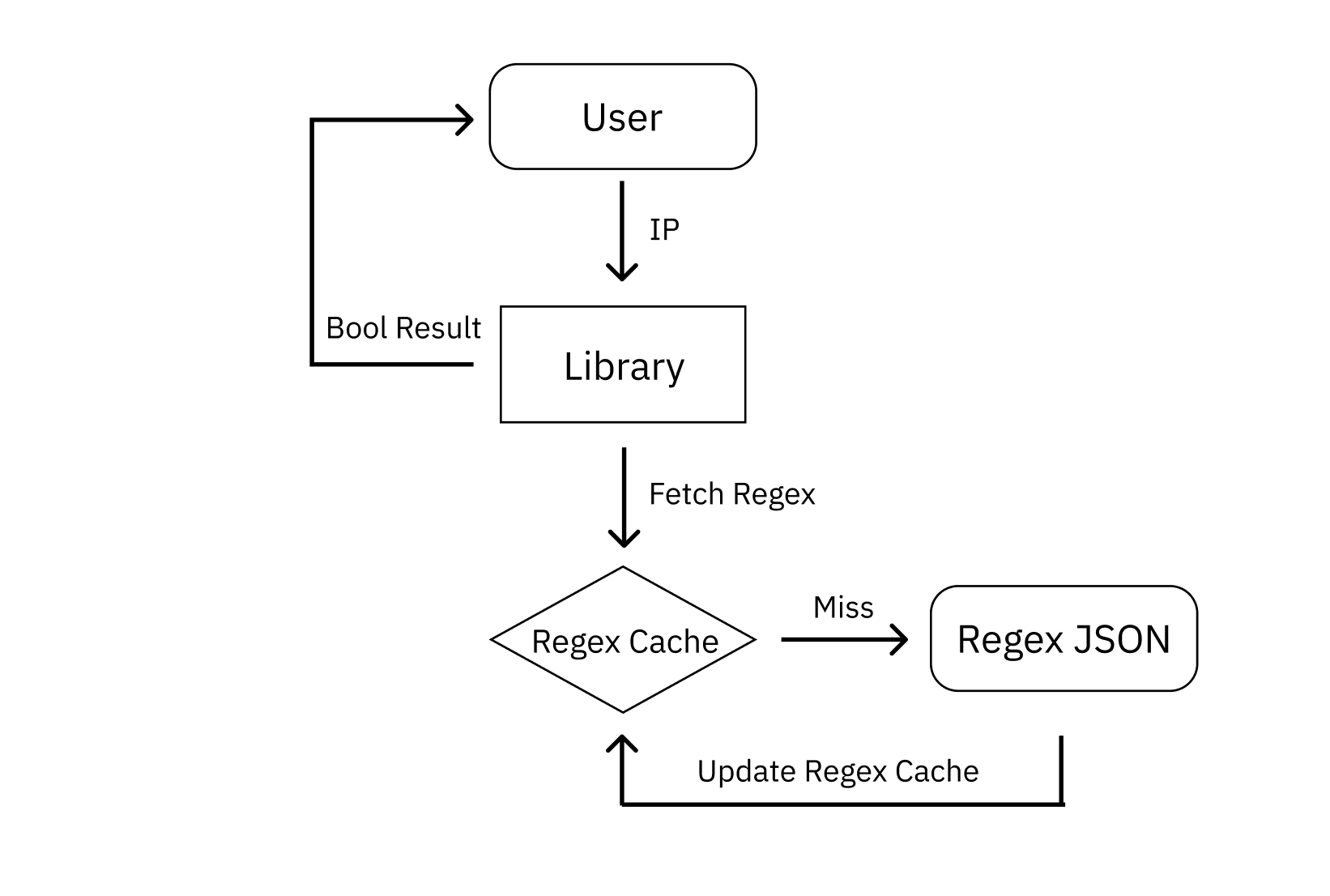
Since the required function is simple from the user’s perspective, I abstracted the complexity behind a minimal interface.
Users can verify whether an IP is in a cloud range by calling only the isServerIP function. They can also pass Provider and Region parameters to apply verification conditions.
When a user requests IP verification, the library first checks locally stored provider-based regex cache in Map format.
If cache exists, it returns the provider’s regex list, and the library verifies whether there is any matching range among the range regexes and responds with the result. Because inclusion must be checked at range level, the entire list is examined.
If cache does not exist, it reads the provider’s regexes stored in JSON files and loads them into cache.
Troubleshooting
1. Range Data Storage Method
Cloud providers publish broad IP ranges. Therefore, if all IPs corresponding to a range are stored and loaded one by one as strings, it was expected to consume excessive space and also make verification very slow.
To solve this, ranges needed to be compressed to occupy less space.
Cloud providers publish ranges in CIDR format. Taking inspiration from this, I came up with converting CIDR to regex.
By using regex, full range data can be compressed into a single-line string by more than 99.97%, and whether an IP is included in the range can be verified in one operation.
2. Computing Resource Management
However, no matter how much ranges are compressed, loading all range data from multiple clouds into memory still occupies a non-trivial amount.
To solve this, I adopted a lazy-loading approach that stores range regex files on disk and reads them only when needed. This allows loading only required parts without keeping all regex data in memory. Also, since regex data is stored independently of instance runtime, there is no need to regenerate heavy regex data every time an instance restarts.
But if implemented only with simple lazy loading, frequent disk I/O would occur, which would heavily burden servers and cause high latency in high-traffic environments. To solve this, data needed to be cached in memory.
Then what should the caching key be?
Individual ranges could not be cached. Because cloud server IPs change unpredictably within region-assigned ranges, cached ranges become meaningless if attackers switch to other ranges and send requests.
Likewise, selective caching by region was not feasible. In most use cases, there is either no demand for region-specific traffic designation or it is unpredictable.
Therefore, I ultimately chose provider-level caching. For verification requests for each provider, data is read from disk and loaded into memory only on the first request, and cached data is used afterward. This limited disk I/O to one time for verification cases where provider is specified.
For verification requests without provider specification, verification across all providers’ ranges is required, so all provider data is cached in memory. In such cases, memory reduction from lazy loading is limited, so I recommend first operating with full verification, then reviewing verification statistics and switching to specifying only actually needed providers.
3. Handling Cloud IP Volatility
As explained in the goals above, cloud IP ranges change frequently.
To reflect this, I provided a function to refresh IP range files so that ranges can be updated at runtime regardless of the library version.
This allows reflecting the latest ranges without instance restart or library update, and enables inserting refresh logic at the application’s desired timing, such as scheduling or event triggers.
Result
The library adopted in-house was adapted for general use and released as open source.
There are still tasks remaining, such as improving documentation and adding asynchronous processing. I plan to address them one by one and keep improving. Contributions are always welcome!
